
跳表的定义
什么是跳表?顾名思义就是可以进行跳跃查找的表(有序链表),跳跃的实现是通过建立多级索引来实现的。为什么要跳跃?传统的有序链表只能从头查到尾来查找指定元素,而跳表可以通过索引,快速进行二分查找,在最好和最坏情况下都能实现平均O(logn)的查找效率。跳表的数据结构如下图:
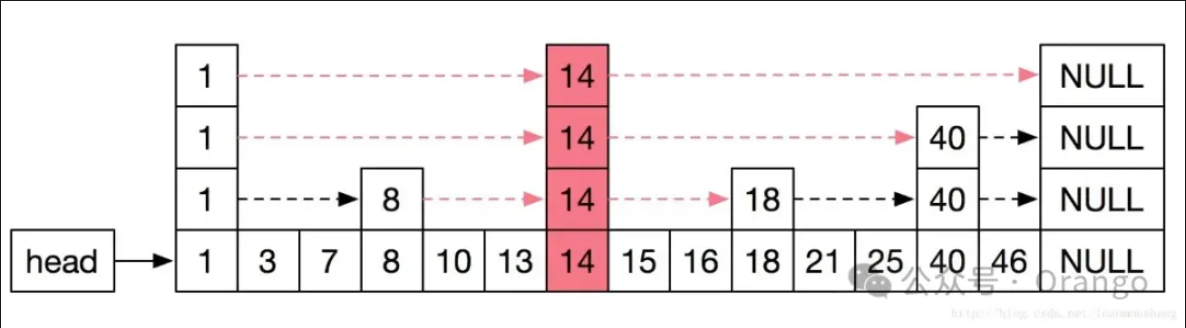
由图可以看出,上一层的索引是下一层的子集,索引的建立并不是简单地通过奇偶次序建立,而是随机建立,因此也可以说它是一种随机化的数据结构。每一层都会有以一个固定的概率建立索引(通常是0.5)。
// 跳表节点
type Node struct {
key int
val interface{}
forward []*Node //指向下一个节点,其中索引表示当前层数
//例如14的forward数组:[15,18,40,Null]
}
// 跳表
type SkipList struct {
head *Node
level int
}跳表的操作
查找元素
查找操作从最上层开始,遵循如下规则:
若当前元素小于待查找元素则继续向右搜索
若查找到为NULL或者大于待查找元素,则返回上一个节点并向下一层
假设查找21,查找路径为:1 -> 14 -> Null -> 14 -> 40 -> 14 -> 18 -> 40 -> 18 -> 21,总共查找7次即可找到(链表需要11次)。
func (s *SkipList) Search(key int) (interface{}, bool) {
node := s.head
for i := s.level - 1; i >= 0; i-- {
for node.forward[i] != nil {
if node.forward[i].key == key {
return node.forward[i].val, true
} else if node.forward[i].key > key {
break //向下一层
}
node = node.forward[i] //移动到当前位置
}
}
return nil, false
}插入元素
向跳表中添加节点等价于添加一个高度为level列(比如上图的14所在列),插入的位置可以通过搜索得到,插入的level可以使用随机化决策确定。其中,随机化决策规则如下:
初始时level=1
产生的随机数小于阈值p(通常设为0.5)并且层级没有达到最大值,则层级+1,否则返回当前层级作为新插入元素的高度
func (s *SkipList) randomLevel() int {
level := 0
for level < maxLevel && rand.Float32() < 0.5 {
level++
}
return level
}插入元素的基本步骤如下:
查找插入位置,查找过程中使用update[i]记录每一层最大节点的位置
得到level
创建新节点,将高度为level的列插入到update[i]之后
func (s *SkipList) Insert(key, val int) {
level := s.randomLevel()
if level > s.level {
level = s.level + 1
}
newNode := NewNode(level, key, val)
update := make([]*Node, level)
node := s.head
for i := s.level - 1; i >= 0; i-- {
for node.forward[i] != nil {
if node.forward[i].key == key {
node.forward[i].val = val
return
}
if node.forward[i].key > key {
break
}
node = node.forward[i]
}
if i < level {
update[i] = node
}
}
for i := 0; i < level; i++ {
newNode.forward[i] = update[i].forward[i]
update[i].forward[i] = newNode
}
if s.level < level {
s.level = level
}
}删除元素
删除元素相当于删除该元素所在的列。算法步骤如下:
首先查找该元素,过程中使用update[i]记录待删节点在每一层前面一个元素的位置
删除update[i]
若有则删除空链
func (s *SkipList) Delete(key int) {
update := make([]*Node, s.level)
node := s.head
for i := s.level - 1; i >= 0; i-- {
for node.forward[i] != nil {
if node.forward[i].key == key {
update[i] = node
break
}
node = node.forward[i]
}
}
for i := 0; i < s.level; i++ {
if update[i] == nil || update[i].forward[i] == nil || update[i].forward[i].key != key {
continue
}
update[i].forward[i] = update[i].forward[i].forward[i]
if s.head.forward[i] == nil {
s.level--
}
}
}跳表的应用
作为一种可以快速查找、新增与删除的数据结构,跳表被用在很多地方,例如:
Redis的zset:在Redis中,跳表被用作有序集合(Sorted Sets)的底层实现。有序集合是一种可以存储非重复字符串元素的数据结构,每个元素都关联一个浮点数分数,用于排序。跳表提供了一种高效的方式来维护这种有序的数据结构。
LevelDB/RocksDB:LevelDB和RocksDB是由Google开发的开源键值存储库,它们在内部使用跳表作为内存中的写缓冲区(MemTable)。当新的键值对被写入数据库时,它们首先被插入到跳表中。跳表提供了一种高效的方式来查找和更新这些键值对。
Apache HBase:Apache HBase是一个开源的、非关系型、分布式数据库,它使用跳表作为内存中的数据结构,用于存储新写入的数据,直到数据被刷新到磁盘。
相关链接:
跳表Wiki介绍:
https://oi-wiki.org/ds/skiplist/
Leetcode相关题目:
https://leetcode.cn/problems/design-skiplist/description/
评论