
一、索引的原理
索引是数据库中加快检索速度的数据结构,我们知道,能够实现快速检索的数据结构通常有哈希表、二叉树、多叉树等,索引就是根据这些数据结构的原理实现的。
Hash索引
Hash索引是利用Hash函数来对数据表中的数据增加索引,当对某一列的数据增加索引时,SQL首先会对该列的数据计算哈希,然后将哈希结果和地址存到索引文件中。
进行Hash索引查找记录时,要读取到记录并比对原值(由于存在哈希碰撞)
局限:
Hash索引只能进行=,IN,<=>等值查询,因为Hash建立的索引是无序的。
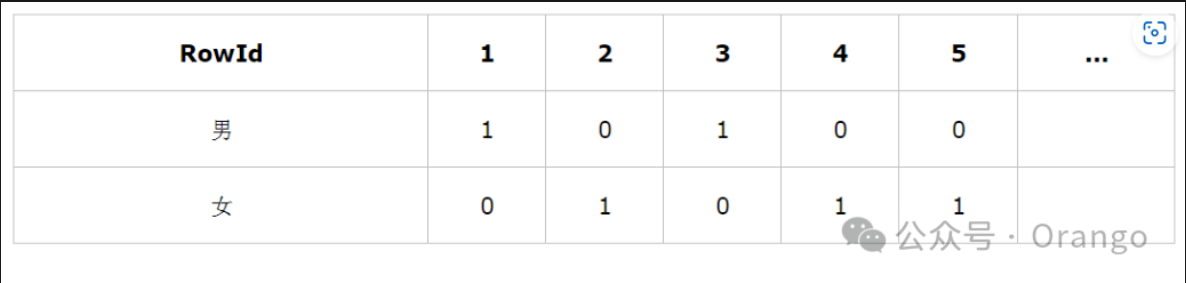
哈希碰撞会降低查询效率,例如性别。
2. BTree索引
利用B-树和B+树来实现索引,BTree索引的根节点在内存中,查找一个节点的时间复杂度为O(logdN),d为出度,N为节点总数。
B+树只在叶子节点存数据,所以非叶子节点可以存储子节点地址信息空间就更大,出度就更高,查询效率更高。所以MyISAM、InnoDB使用B+树实现索引。不同的是,在MyISAM中,叶子节点存储指向具体记录的连接,而InnoDB存储数据。
3. 位图索引
如果要建立索引的值只有几个固定的值,不适合用以上索引,因为Hash索引会存在大量碰撞,而BTree索引存在大量相等的节点。
位图索引的基本逻辑是向量化和位逻辑运算,适合为枚举属性建立索引:
二、索引生效分析
在查询语句前使用EXPLAIN或者DESC来分析索引生效的过程。例如使用EXPLAIN会出现以下字段:
type:(连接类型)ref表示使用索引,fulltext全文索引,all全表扫描
possible_key:可能用到的索引
key:最终使用的索引(add index 的索引name)
key_len:索引长度
......
三、索引的使用
第一节中,按照原理将索引进行分类,而这一部分从使用场景对索引进行分类:
唯一索引:不允许两条记录有相同索引值的索引
主键索引:如果某个属性被定义为主键,自动创建索引
聚簇索引&非聚簇索引:表中的物理顺序与索引的逻辑顺序一致,是聚簇索引
联合索引:将几个列联合起来共同创建索引
过滤索引:建立索引时可以不对所有记录创建索引
四、索引失效
计算与类型转换引发的索引失效
...where age + 1 = 18
...where name = 18 //type name is varchar2. 联合索引失效
联合索引的最左前缀原理,例如建立(schoolname, classname)的联合索引时,会首先根据schoolname建立排序,然后对schoolname相同的记录再按照classname排序,因此在最终得到的索引中,schoolname是全局有序的,而classname只在schoolname相同是有序。所以使用schoolname检索可以走索引,而使用classname不走索引。所以在建立索引的时候,应该将最可能单独查询的属性放在最左侧。
3. 模糊匹配引发的索引失效
使用通配符开头进行模糊查询,会导致BTree索引失效,正则表达式索引均不生效。
...where name LIKE '%大橘'4. 其他失效场景
使用!=,<>,NOT,因为BTree索引是通过等值计算进行检索的,无法支持非等值计算
使用IN,NOT IN,因为效率还不如全表扫描,可以使用BETWEEN代替IN
使用IS NULL,IS NOT NULL,=NULL,!=NULL会导致失效,因为NULL值无法通过索引找到,可以使用0,空字符串来避免出现NULL值。
五、 索引的利弊
空间换时间,且每次数据变更需要重新建立索引,因此不建议对读少写多的属性建立索引。
🌈下一篇将会对MySQL的锁以及事务ACID进行分析,点个赞再走叭!
评论